softmax 简介
总体概览
本文材料参考了UFLDL的网上资料.
Softmax回归用于处理n分类的问题,是一个判别模型.在神经网络相关的模型中经常用到.
条件随机场
先看一个简单的无向网络图
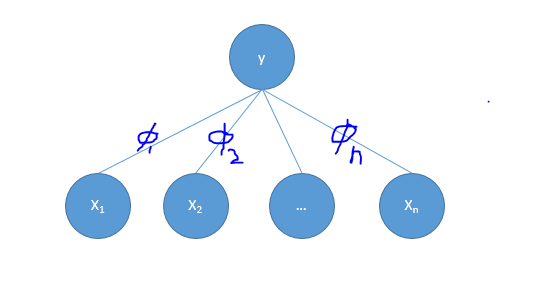
定义操作$\phi = \lbrace \phi_1(D_1), \phi_2(D_2),….\phi_n(D_n) \rbrace$
对于联合分布$P_\phi(X,Y) = \prod_{i=1}^N \phi_i(D_i)$, $X = (x_1,x_2, … x_n)$, 这里是没有归一化的联合分布
定义$Z_\phi(X) = \sum_Y P_\phi(X,Y)$, 对Y的不同取值,计算联合分布后求和. 归一化因子
归一化的条件分布
上述就是条件随机场的一个例子.
softmax
softmax的代价函数
关于$\phi_1(D_1)$,其中$D_1$可以定义为$(x_1,y)$, 而操作$\phi$可以有多种定义,譬如可以定义为$x_1,y$共同出现的次数等等.
对于一个二分类问题$Y=[0,1]$, 定义 $\phi_i(x_i,Y)=e^{w_i * x_i * 1\lbrace Y=1 \rbrace}$, 于是有下面的联合分布
条件分布为
为了计算方便,对上面的式子取log,同时取负值,就是logistic回归做二分类的代价函数
对于K分类有如下条件分布
对上式取log,同时取负值,就得到softmax的代价函数,同时在机器学习中考虑batch(mini batch)-learning对M个样本进行学习时
上面的式子写的过于琐碎,把$w,x$写为向量形式则有$w^Tx=\sum_i w_i x_i$, 于是代价函数就写为
因为我们是计算代价(损失)函数,所以需要取负值.
取log是为了计算方便,最大化某个函数等价于最大化其取log后的函数
softmax的梯度
在机器学习中除了要计算代价函数,在优化时还需要给出梯度(一阶偏导)
L2 Regularization
UFLDL上关于softmax一个特点的说明, Softmax回归有一个不寻常的特点:它有一个“冗余”的参数集.
进一步而言,如果参数 $(w_1, w_2,\ldots, w_k)$ 是代价函数 $J(w)$ 的极小值点,那么 $(w_1 - \psi, w_2 - \psi,\ldots, w_k - \psi)$ 同样也是它的极小值点,其中 $\psi$ 可以为任意向量. 因此使 $J(w)$ 最小化的解不是唯一的。
证明很简单,请参考UFLDL.
直观的理解也就是k分类,其实只要识别出k-1个类别就可以了. 本质上这个最优参数 $(w_1,w_2,\ldots,w_k)$ 中的向量线性相关.最优参数有无穷多个,是一条直线而不是一个点.
但 $J(w)$ 仍然是一个凸函数,因此梯度下降时不会遇到局部最优解的问题.但是二阶偏导的Hessian矩阵是奇异的/不可逆的,这会直接导致采用牛顿法优化就遇到数值计算的问题.
我们通过添加一个权重衰减项 $\frac{\lambda}{2} \sum_{j=1}^k \sum_{i=0}^{n} w_{ij}^2$ 来修改代价函数, (注,$w_j$为n+1维空间向量,一共k个)这个衰减项会惩罚过大的参数值,现在我们的代价函数变为:
有了这个权重衰减项以后($\lambda > 0$),代价函数就变成了严格的凸函数,这样就可以保证得到唯一的解了.此时的 Hessian矩阵变为可逆矩阵,并且因为 $J(w)$ 是凸函数,梯度下降法和 L-BFGS 等算法可以保证收敛到全局最优解.
修改后的代价函数的梯度公式为
总结
条件随机场是softmax的一般化形式, 而softmax是logistic回归的k分类的一般化形式. 当用softmax做二分类时等价与logistic回归. UFLDL上也有简单的数学推导
参考
UFLDL http://ufldl.stanford.edu/wiki/index.php/Softmax_Regression
CRF https://en.wikipedia.org/wiki/Conditional_random_field